Toute personne impliquée dans la conception Web ou de développement a rencontré le terme sémantique en référence à l’html5 et Internet en général. Ce terme est souvent problématique naturellement source de confusion pour beaucoup d’entre nous, en particulier, car il y a un manque évident de consensus sur sa définition dans certains contextes. Dans cet article, nous allons explorer l’Html5 et tenter de comprendre ce qu’il le rend plus sémantique que ses prédécesseurs.
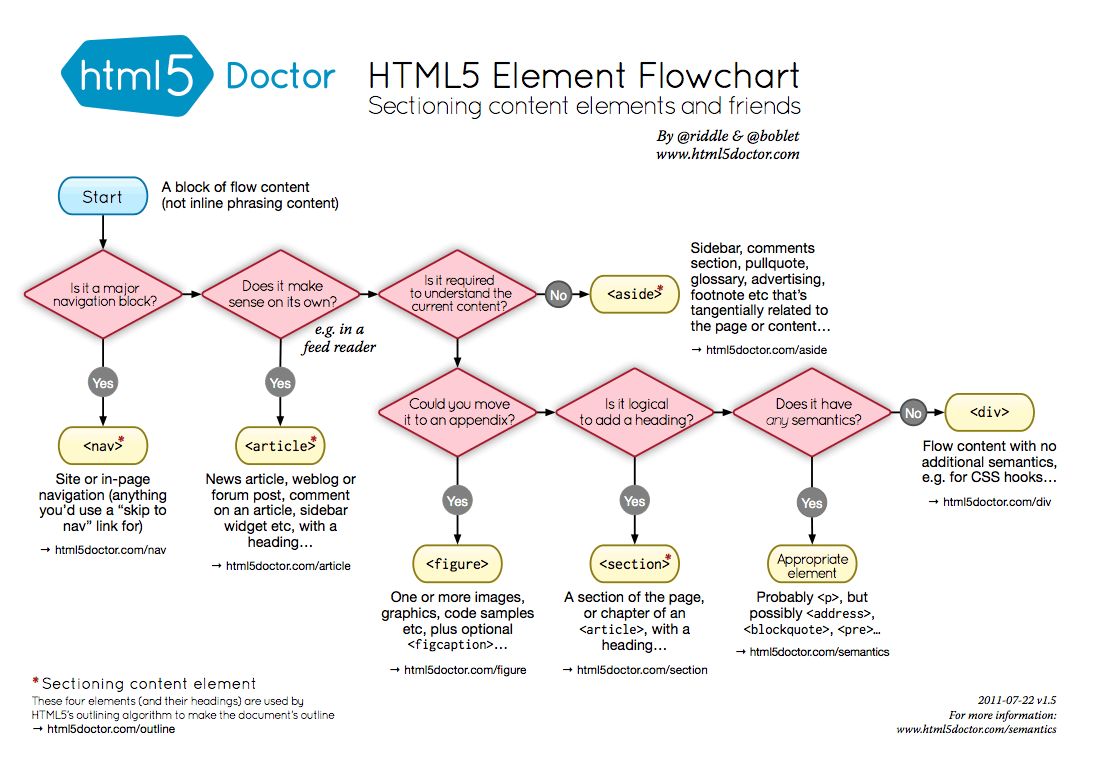
Diagramme des éléments sémantique en html5
Le sens de la sémantique
Le concept de la sémantique vient du domaine de la linguistique consacrée à l’étude du sens. Avec des langues naturelles telles que le français, nous distinguons entre la syntaxe (la grammaire) et le sens. Si vous pensez à une phrase, le sens a à voir avec la façon dont les gens l’interprètent : « Le chat a ronronné sur moi toute la journée. » La sémantique se rapporte à l’aspect de la phrase qui permet aux gens de le lire pour comprendre le message qu’il contient. En collaboration avec la syntaxe, la sémantique est une grande partie de ce qui facilite la communication par le langage. Lorsque nous parlons de la sémantique par rapport à l’Html, nous parlons de la communication entre les programmes d’ordinateur, pas les humains. La sémantique html vise essentiellement à améliorer la mesure dans laquelle les applications peuvent traiter ou interpréter le contenu d’Internet. Par exemple, considérons l’extrait suivant, la page contenant certaines des structures html plus autonomes :
Le chat a ronronné sur moi toute la journée.
<img alt= »chat ronron » src= »images/chat_ronron.png » title= »le chat ronronne » />
Les éléments (et attributs) donnent des informations sur la façon que le navigateur va présenter le contenu à l’utilisateur. Les éléments de paragraphes seront par défaut affichés par un espace au-dessus et en dessous d’eux, les éléments d’image sont affichés en utilisant le fichier image inclus dans l’attribut src et ainsi de suite. Lorsque le navigateur rencontre chacun de ces éléments, il rend le contenu d’une manière particulière qui est finalement déterminée par les balises utilisées.
Les structures html ont déjà une signification
Il est important de comprendre que l’Html5 n’a pas pour rôle d’introduire une sémantique au format Html pour la première fois. L’Html à déjà un niveau de sémantique intégré. Les structures existantes Html sont significatifs à des degrés divers. Si vous regardez cet élément familier Html inclus dans l’extrait ci-dessous vous verrez où je veux en venir :
<img alt= »chat ronron » src= »images/chat_ronron.png » title= »le chat ronronne » />
Bien qu’il soit abrégé, le nom de l’élément img indique quelque chose de significatif sur le contenu de la balise, c’est-à-dire que c’est une image. De cette façon, vous pouvez penser à l’aspect sémantique html comme étant semblable aux méta données, le rôle de la balise de l’élément et les noms d’attribut sont de décrire les données.
Rappelez-vous au commencement, le contenu était séparé du style
Certaines de ces structures que nous avons utilisées en Html indiquent au navigateur le style des éléments de contenu dans une page. Depuis un moment déjà, nous avons été encouragés à séparer la mise en forme d’une page de son contenu. Par exemple, nous avons remplacé la balise i avec em, ce qui est plus significatif et ne dit pas exactement comment le navigateur doit afficher le texte dans l’élément. Le but d’utiliser em est de transmettre des informations sur la nature de l’élément de contenu, plutôt que des informations à propos du style. Les em évidemment influe sur le style, qui est la principale raison pour laquelle nous l’utilisons, mais il laisse les détails du style au navigateur et / ou le code CSS idéalement séparé du balisage de la page. La sémantique Html5 est une grande étape dans ce processus. Le but ultime est de créer un système dans lequel les applications ont accès à un plus grand niveau de signification
N’est-il pas similaire au langage XML ?
Si vous avez utilisé l’Xml dans le passé, vous avez une certaine familiarité avec les concepts de balisage sémantique. Par exemple, lorsque vous créez un document Xml pour un ensemble de données, vous choisissez les éléments et attributs à des éléments de modèle dans les données. Idéalement, les noms d’éléments et d’attributs définissent les éléments de données d’une manière significative :
<nouvel_article piece_id= »2468″>
Didier Dupont
21 janvier 2013
</nouvel_article>
Le développeur a choisi ici des noms qui décrivent de manière intuitive les valeurs de données en cours de modélisation. Avec l’Html5, vous ne pouvez pas choisir vos propres éléments, car ils ne sont pas librement extensible. Les choix des structures ont pour but d’obtenir un sens plus essentiel par rapport aux versions précédentes.
Différents types de sens
Nous avons parlé de la signification, mais en fait, il y a différentes façons dans lequel un élément ou un extrait d’autre code peut être significative. La balise img est significative, elle raconte quelque chose sur le contenu de l’élément, en décrivant ce qu’il est. Certains des nouveaux éléments Html5 comme header et footer sont significatifs, ils indiquent quelque chose sur le rôle ou le but de l’élément dans la structure globale d’une page.
Qu’est-ce que cet aspect amélioré significative de l’Html5 implique ?
L’Html5 a quelques nouveaux éléments avec lesquels vous pouvez inclure plus d’information sémantique dans votre balisage des pages. Il y a une multitude de nouveaux éléments, nous allons en examiner ici quelques-uns. La balise d’en-tête (header) indique une information concernant le contenu de l’élément et de son rôle dans la structure de la page :
<header>
<h1>Outil seo</h1>
</header>
L’élément d’en-tête peut contenir d’autres éléments et a tendance à inclure au moins un élément de tête. La balise de bas de page (footer) est similaire, avec la balise, le but est de nouveau d’exprimer quelque chose de significatif sur le contenu de l’élément et sa relation avec le reste de la page :
<footer>
Informations de bas de page
</footer>
La balise nav décrit l’objet d’une section de page, c’est à dire qu’elle contient des liens de navigation :
<nav>
<ul>
<li>
<a href »home.php » title= »home »>Index du site</a>
</li>
<li>
<a href »nouvelles.php » title= »les nouvelles »>Les nouvelles</a>
</li>
<li><a href= »contact.php » title= »contact »>Contactez-nous »></a></li>
</ul>
</nav>
L’élément section contient généralement un groupe d’articles sur le même thème, souvent en collaboration avec un en-tête. L’élément de section a une signification assez abstrait, mais il est néanmoins significatif :
<section id= »vue »>
<h2_>Gérard Depardieu s’exile</h2_>
Gérard Depardieu à décidé…
<img alt= »l’exile » src= »images/gerard-depardieu.jpg » title= »Depardieu l’exilé » />
</section>
L’élément article est semblable, utilisé pour définir un élément qui est autonome :
<article>
<h2 >Le miracle</h2 >
Le miracle du chat perdu s’avère…
</article>
Une balise aside indique le rôle d’un élément par rapport à son contexte dans la page, comme dans la version étendue suivant le code de l’article ci-dessus:
<article>
<h2 >Le miracle</h2 >
Le miracle du chat perdu s’avère…
<aside>C’est en 2003 que le miracle survient…</aside>
</article>.
Ce ne sont que quelques-uns des nouveaux éléments Html5 offrant des améliorations sémantiques, d’autres incluent les médias et les éléments de saisie utilisateur ainsi que des attributs supplémentaires. L’inclusion de micro-données dans l’html5 fournit également une possibilité accrue, y compris l’information sémantique dans les pages et les applications. Comme vous pouvez le voir, certains de ces nouveaux éléments sont significatifs tant en termes de contenu et qu’à la structure.
Pensez à certaines des vieilles balises, telles que div. L’élément div est tout simplement un morceau d’une page. Le nom de la balise ne nous dit absolument rien sur le contenu de l’élément ou de son rôle au sein de la page. En d’autres termes, l’étiquette transmet très peu de sens. Beaucoup de balises de longue date n’ont généralement aucune signification du tout ou dans certains cas générique, un sens vaguement défini. Chaque élément dans une page a été contenue dans un d’un ensemble de catégories d’éléments très généraux. Les nouvelles balises Html5 nous permettent de définir le contenu en utilisant des termes plus spécifiques.
Pourquoi avoir fait un cours théorique ?
Je devais absolument introduire par des notions en Html5. Ce qui nous permettra de mieux comprendre le fond de ma problématique posée.
Comme nous l’avons vu, la sémantique Html5 nous permet de créer un code de balisage qui décrit des éléments de contenu.
- Le balisage sémantique rend les contenus et les données plus consultables. Les pages web ne sont bien sûr pas seulement affichée dans le navigateur web, ils sont également traités par d’autres programmes tels que les robots des moteurs de recherche. Depuis le balisage sémantique est conçu pour permettre aux applications interpréter les pages web de manière plus significative, ce qui devrait à terme améliorer la qualité de la recherche. Tim Berners-Lee a souvent cité le « rêve » pour le Web, les ordinateurs seraient capables d’analyser toutes les données en ligne. Ce qui pourrait être très loin, mais la poussée sémantique de l’Html5 est motivée par ce type d’objectif à long terme.
- L’accessibilité est l’un des principaux avantages de balisage sémantique. Les outils d’accessibilité peuvent bénéficier grandement de l’accès plus significatif du contenu Internet. Ces outils comprennent modules complémentaires du navigateur pour les utilisateurs ayant une vision limitée, de problème d’audition, de difficultés d’apprentissage etc.. Le balisage sémantique est plus facile pour une application de traitement de contenu web et le résultat pour communiquer le message original à l’utilisateur de manière à ce qu’il convienne à leurs besoins. Ce concept s’étend au-delà de l’accessibilité, grâce à des techniques telles que la conception. Le résultat est une approche plus globale de diffusion de contenu.
- Le balisage sémantique améliore la cohérence, tant que les éléments de contenu sont plus logiquement attribuables à des types d’éléments particuliers. Ceci est en contraste avec les modèles plus anciens, dans lequel les éléments peuvent souvent tout aussi logiquement être contenues dans toute une gamme de types d’éléments différents.
Alors, et le référencement dans tout ça ?
Ce n’est pas seulement facile à comprendre pour nous, mais aussi beaucoup plus facile pour un Bot Google à explorer et à indexer un site structuré en Html5. Les méthodes traditionnelles pour définir un en-tête et un pied de page se composait de la balise div avec un identifiant unique. Bien que ce soit un moyen efficace de faire les choses, il est bien plus désordonnée que d’utiliser des balises spécifiques pour chaque zone de contenu. Quand quelques experts indiquent que l’Html5 diminue le champs d’application du référencement, différentes preuves contre cette affirmation.
Si cela vous intéresse, je vous propose l’article que j’avais rédigé sur les effets de l’html5 qu’ils pourraient avoir sur le référencement.