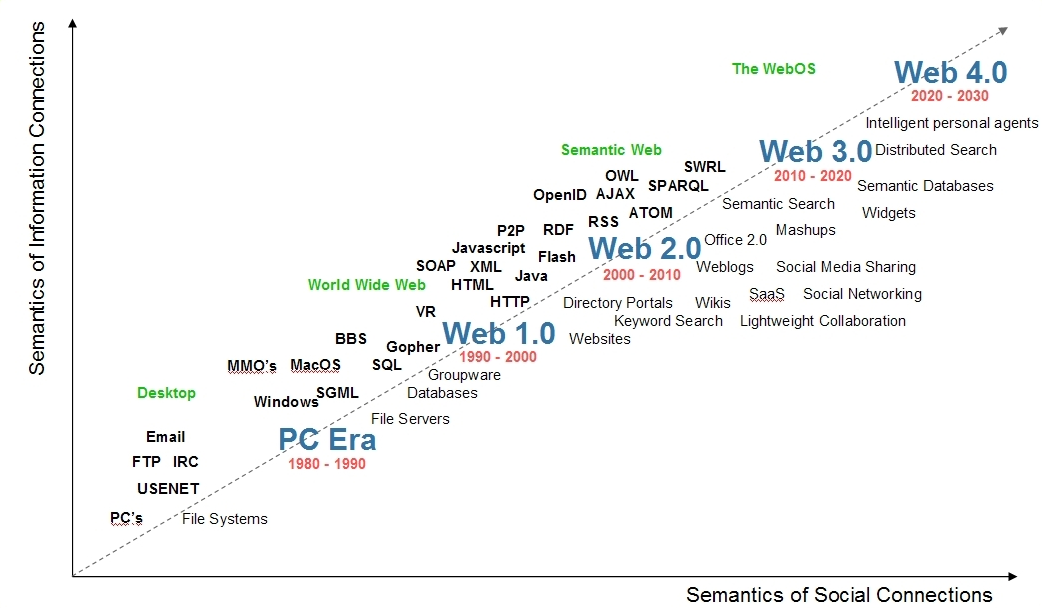
Le web sémantique : Présent dans la recherche de tous les jours
En 1999, Tim Berners-Lee a décrit sa vision de l’avenir d’Internet. Il décrivit les ordinateurs étant capable d’analyser et de comprendre les mêmes informations que nous, et de devenir des assistants virtuels personnalisés. Imaginez l’application de calendrier sur votre appareil mobile observant un conflit d’horaire lorsque vous commencez à réserver un voyage sur Weekendesk. Ou que votre ordinateur effectue toutes les recherches nécessaires pour justifier votre décision et établit un rapport de recherche détaillé à l’appui d’une décision prête pour vous dans la matinée. Pour beaucoup, c’est la véritable destination d’Internet, et tout le partage social qui a attiré l’attention de tout le monde dans le web 2.0 est un aperçu simple de ce qui est à venir. Un auteur du blog, a décrit en disant: » C’est une orgie de données et votre serveur y est invité « .
Depuis une dizaine d’années, un mouvement appelé le Web sémantique (hyper-médias) a été adopté pour permettre cette vision. On pense que par bien annoter un document HTML, permettra à un ordinateur de consommer et de comprendre l’information, un peu comme un humain le ferait et donc être en mesure de prendre des décisions éclairées et à agir en notre nom. Pour ce faire, il doit y avoir la structure, les définitions relationnelles et des protocoles d’annotation de plusieurs vocabulaires descriptifs et suivis. Jusqu’à présent, l’adoption a été anémique.
Cependant, pour de nombreuses raisons, l’effort a jusqu’ici été scindé en factions de diverses technologies concurrentes. La création et le soutien limité par les navigateurs ainsi que les moteurs de recherche ont limités les précoces à explorer la technologie plus profondément.
Mais récemment, cette situation a changé depuis l’apparition de l’HTML5, technologie prenant en charge le marquage sémantique dans tous les navigateurs modernes. Les moteurs de recherche ont commencé à récompenser les sites Web utilisant les Rich Snippets en affichant dans leurs résultats de recherche les données sémantiques ( étoiles d’évaluation, image de profil google, etc.). Des rapports ont été rédigés, beaucoup de firmes ont vu leur trafic augmenté près de 30 %, en raison de leurs implémentations de la norme RDFa et des Rich Snippets.
Récemment d’autres entreprises utilisent également des balises sémantiques. Facebook ont été les premiers à se démarquer en utilisant la norme RDF avec la création de l’OpenGraph en 2009 et ont récemment commencés à utiliser le marquage de profils utilisateurs et événementiel avec les micro-formats hCard et hCalendar. Google a poussé l’authentification des auteurs et lds ouvrages rédigés avec l’annotation XFN rel= »me ». Yahoo Tech et LinkedIn ont tout deux adoptés également la norme des micro-formats dans leurs données.
En réponse à cette confusion et complexité, un consortium des principaux moteurs de recherche, y compris Google, Yahoo, Microsoft et Yandex, se sont réunis pour créer une approche standardisée, appelée Schema.org. Elle suppose l’utilisation des micro-données à grande échelle plutôt que RDF / RDFa et constitue une ressource unique pour les principaux vocabulaires sémantiques à utiliser. L’espoir est que, en simplifiant la technologie et la standardisation, ces obstacles à l’adoption se verront réduits et que la plupart des industries commencent à adopter cette technologie.
Alors, comment peut-on mettre en oeuvre une annotation sémantique ?
Il y a deux cadres d’annotation primaires qui sont le langage de définition de ressource (RDF / RDFa) et Microformats. RDF peut être utilisé avec le balisage du document HTML avec ce qu’on appelle Sujet-Prédicat-Objet triple. C’est un langage robuste qui est le plus couramment utilisé pour d’autres ensembles de données fiables qui nécessitent des données de liens profonds. Il a été critiqué pour sa complexité, cependant une révision récente appelée RDFa a été mise en place ce qui rend la technologie plus facile à utiliser, avec un accent sur l’utilisation d’attributs. Voici un exemple de ce que pourrait ressembler un objet simple en RDFa :
</pre> <div xmlns:v=”http://rdf.semantic-vocabulary.org/#” typeof=”v:Person”> <p>Name: <span property=”v:name”>Rémi Morin</span></p> <p>Title: <span property=”v:title”>Référenceur web, chargé de veille emarketing</span></p> </div> <pre>
Les Micro-formats quant à eux, ont été développés visant la simplicité pour une implémentation dans un document HTML. Les Micro-données sont un sous-ensemble des Micro-formats que Schema.org a mis en place. Créant sa propre API DOM dans la spécification HTML5, c’est donc la future norme présumée pour la plupart des sites internet :
</pre> <div itemscope itemtype=”http://semantic-vocabulary.org/Person”> <p>Name: <span itemprop=”name”>Rémi Morin</span></p> <p>Title: <span itemprop=”title”>Référenceur web, chargé de veille emarketing</span></p> </div>
À un certain niveau, les concepts sont assez simples, mais il y a de nombreuses ontologies et vocabulaires sémantiques qui ont été définis et sont référencés dans le but de donner un sens à votre RDF ou attributions Microformat. Remarqué la référence sémantique vocabulary.org ci-dessus ? Elle fait appel à un schéma défini hCard, ou dans l’exemple suivant est une personne qui y est définie. Schema.org a défini un grand nombre d’entre eux directement pour les micro-données, mais il en existe d’autres comme base Dublic, DocBook et les Goodrelations qui est très populaire en particulier pour le commerce électronique. Il y a des plugins disponibles pour un grand nombre CMS, principalement dans le commerce électronique pour aider à mettre en place un balisage sémantique.
Imaginez le web 4.0
Tom Jenkins, président exécutif d’Open Text a récemment fait l’objet d’un discours sur l’apparition du web 3.0 web sémantique et d’Internet objet ainsi que de ses prédictions pour le Web 4.0. Jenkins a noté que » Les natifs du numérique, décrits comme super-connectés fous de technologie âgées de 30 ans et au-dessous, demandent d’avantages de gadgets et de nouvelles applications qui vantent les gains de productivité et de temps. C’est cette demande qui est le moteur de l’arrivée précoce du Web 3.0, ou le Web sémantique. »
Jenkins prédit que le Web 4.0 arrivant dans notre vie de tous les jours dans les cinq ans : » Les environnements virtuels ne sont plus limités aux laboratoires de recherche et cette paire de lunettes 3D pour les films peuvent être utilisés plus souvent que jamais. » Jenkins perçoit le Web 4.0 basé sur la virtualisation, en déclarant : » Pensez à un monde virtuel, se représenter comme étant un avatar, possédant une paire de lunettes 3D virtuels et que l’on puisse marcher dans les nuages. »
Jenkins a également exprimé le besoin croissant de gestion des connaissances et le danger pour les entreprises d’ignorer les médias sociaux: « Environ 45% des entreprises au niveau mondial interdisent l’accès des employés aux sites de médias sociaux. » Jenkins avertit que ces sociétés finiront par «perdre leur compétitivité» et exhorte le développement des politiques de l’entreprise pour guider utilisation des médias sociaux.
Je vous invite à lire un article intéressant avec l’arrivée du Knowledge Graph de Google en France complétant mes arguments illustrés ici ainsi que dans un de mes articles sur la présentation du graphe de connaissance dynamique de google lorsqu’il était sorti aux Etats-Unis que j’avais rédigé auparavant .
Article édité le 07/12/2012
Rémi Morin
Veilleur - Référenceur Gestion de l'identité numérique des entreprises soucieuses de leur e-reputation, et conscientes de la plus-value que peut apporter la bonne gestion de leur présence en ligne.
Follow Me:




